
仮想エージェント スロット作成の推奨事項と制限
仮想エージェントを有効にすると、それを使用して AI 搭載スロットを構成できます。仮想エージェントを使用してスロットとスロット タイプを構成する前に、Genesys 開発者が大規模言語モデル (LLM) スロットに対して推奨する制限、考慮事項、およびヒントを確認してください。次の表は、仮想エージェントで使用できるスロット タイプを定義しています。
| スロットタイプ | 説明 | 例 |
|---|---|---|
| 数値シーケンス |
ボット参加者によって提供される固定長の数値シーケンス。 |
|
| 文字と数字の組み合わせ |
ボット参加者によって提供される固定長の英数字シーケンス。 |
|
| Free-form |
ボット参加者が特定の説明とともに提供する自由形式のシーケンス。 |
|
次のセクションでは、スロットの制限、これらのスロットがボット参加者による明示的な確認と否定を処理する方法に関する情報、および具体的な例について説明します。
数値スロット
ボットが抽出されたシーケンスの一部として数字文字のみを考慮するようにする場合は、このスロット タイプを使用します。ボットは他の文字を認識しません。
- 設定された maxLength 値を超えるエンティティは受け入れられません。たとえば、エンティティ値が「123456」で、maxLength が 7 に設定されていて、顧客が「78」と言った場合、新しく抽出されたエンティティは「12345678」で長さが 8 になったため、ボットは新しいエンティティを noMatch として扱い、残りを「123456」のままにします。
- 明示的でないケースや、抽出されたエンティティの中間部分にあるケースの修正。次の例では、以前に抽出されたエンティティは 1299554464 でした。
修正作業の例:- 「最後の2桁は64から62に変更なし」
- 「最後の2桁は62になるはずです」
機能しない修正の例:
-
- “No 62.”LLM では何を変更すべきかを判断できません。
- 「いいえ、62のつもりでした。」LLM では何を変更すべきかを判断できません。
- 「55を44に変更してください。」このエントリはエンティティの中央にあるため、LLM が判別するのは困難です。
- 「エンティティは 5 から始まる必要があります。」LLM は先頭に 5 を追加するか、または予想どおりに「1299554464」を「5299554464」に修正する場合があります。
-
- LLM では数値が大きくなっても問題は発生しませんが、数値を大きくすると修正が困難になる可能性が高くなります。数値が大きくなるほど、値の先頭または中間を修正するのが難しくなります。この制限のため、Genesys ではマルチスロットの性質の使用を推奨しており、クレジットカード番号が抽出される場合は 4 桁のチャンクでデータを要求します。間違いは最後の 4 桁以内で発生するため、修正が容易になります。
うまく機能するケースは次のとおりです。
- あらゆる長さの数字を簡単に抽出します。たとえば、「私のクレジットカード番号は 0123456789012232 です。」
- 語彙形式の数字を使用して、複数ターンにわたって数字を抽出します。例えば:
- 参加者:「私のカードは0011で始まります」ボット:「今のところ0011を取得しました。続けてください。」
- 参加者:「それから7831」ボット:「今のところ0011 7831を取得しました。続けてください。」
- 参加者:「セブンワンダブルオー」ボット:「今のところ0011 7831 7100です。続けてください。」
- 参加者:「ついに3333」ボット:「0011 7831 7100 3333 という番号ですが、合っていますか?」
- 明示的な修正。たとえば、「最後の 2 桁を 84 から 82 に変更します。」
- LLM では、「Double」を後に続くものの 2 つとして扱います。たとえば、double 2 = 22 です。まず、ASR はこの応答を 22 に変換する必要があります。「トリプル」/「トレブル」はその数字の3つ、「クアドラプル」は4つです。
- LLM は、予想される状況では「Oh」を「0」として扱いますが、「Oh sorry i means」などの予期しない状況では扱いません。
文字番号スロット
このスロットタイプは、参加者が音声アルファベットを使用する場合に抽出中にヒントを提供する場合に使用します。たとえば、 NATO音声アルファベット。たとえば、ユーザーが「アルファの a」と言うと、抽出される文字は「A」になります。
- 設定された maxLength 値を超えるエンティティは受け入れられません。たとえば、エンティティ値が「A12345」で、maxLength が 7 に設定されていて、顧客が「67」と言った場合、新しく抽出されたエンティティは「A1234567」で長さが 8 になったため、ボットは新しいエンティティを noMatch として扱い、エンティティ「A12345」を保持します。
- 複数のターンにわたって重複したキャラクター。ターン 1 で抽出されたエンティティが「AB78G」であり、次のターンで顧客が別の「g」から開始する場合、LLM は誤って「AB78GG」ではなく「AB78G」を返す可能性があります。
- あいまいな訂正。たとえば、「いいえ、AZ と言いました。」1 ターン目に顧客が「A は apple、C 72」と言った場合、それが「AC72」として抽出され、次のターンで「いいえ、AZ と言いました」などの難しい訂正が行われると、あいまいな訂正が発生する可能性があります。
- LLM では、英数字の値が大きくなっても問題は発生しませんが、そうすると修正が困難になる可能性が高くなります。数値が大きくなるほど、値の先頭または中間を修正するのが難しくなります。この制限のため、Genesys ではマルチスロットの性質の使用を推奨しており、パスポート番号が抽出される場合は、3 文字のチャンクでデータを要求します。間違いは最後の 3 桁以内で発生するため、修正が容易になります。
うまく機能するケースは次のとおりです。
- 文字の音声表記、単純に表記した文字、および数字を含む、あらゆる長さの英数字の抽出。たとえば、「私のパスポート番号は、Apple の a、Beta の b、Charlie の c、8909 です。」
- 字句形式の数字を使用して複数ターンにわたって英数字を抽出します。例:
- 参加者:「私の会員番号はAB11で始まります」ボット:「今のところ AB11 を取得しました。続けてください。」
- 参加者:「ではチャーリーのcとゼータのz」ボット:「今のところAB11 CZを取得しました。続けてください。」
- 参加者:「ベータアルファ」ボット:「今のところ AB11 CZ BA を取得しました。続けてください。」
- 参加者:「ついに99」ボット:「AB11 CZ BA 99 を取得しましたが、正しいですか?」
- 明示的な修正。たとえば、「いいえ、最後の文字は c ではなく zeta の Z であるべきです。」
- LLM では、「Double」を後に続くものの 2 つとして扱います。たとえば、double 2 = 22 です。まず、ASR はこの応答を 22 に変換する必要があります。「トリプル」/「トレブル」はその数字の3つ、「クアドラプル」は4つです。
- LLM は、予想される状況では「Oh」を「0」として扱いますが、「Oh sorry i means」などの予期しない状況では扱いません。
フリーフォームスロット
ボットにキャプチャするエンティティのテキスト説明を認識させたい場合は、これらのスロットを使用します。たとえば、通り名、市区町村、PIN コードを含む住所などです。
- 住所
- 特定の国の標準に従った住所形式。ボット参加者は、適切な形式であることを確認するために、提供された説明に頼る必要があります。
- ケース:大文字と小文字の区別は通常は正しいですが、抽出されたエンティティがすべて小文字またはすべて大文字で返される場合もあります。
- メール
- 複数ターンの会話にわたるカスタム ドメイン名の識別が不正確です。電子メールが 1 回のターンで提供されると、より一般的で正確なリターンが発生します。
- ASR 転写でダッシュ、ドット、アンダースコアを変換できない場合。
- 名前
- 長い名前を入力すると、文字が欠落したり、並べ替えられたりします。
各呼び出し後のモデル出力には、抽出されたエンティティと、抽出が完了したかどうか (エンティティ検出ステータスが進行中か完了か) を示すブール値の 2 つの部分が含まれます。フリーフォームの場合、ボットは提供された説明を使用します。
- モデルは説明を使用して、エンティティがキャプチャされているかどうか、または説明に記載されている部分が欠落しているかどうかを判断します。理想的には、説明には、エンティティの内容と、エンティティに含める必要がある他のサブエンティティまたはエンティティの部分が含まれている必要があります。
- 先へスキップすることも可能です。顧客が次のようなことを明確に述べた場合: 「完了しました、これで終わりです、これですべてです、持っていません、わかりません」などの場合、抽出ステータスは完了に変わり、説明に基づいてサブエンティティ コレクションが上書きされます。
フリーフォームスロットの例:ボットがエンティティ検出ステータスを正しく判断できるケース
これらの例では、スロットは person_name であり、人の名と姓を記述します。
- ボット参加者は、エンティティのどの部分が提供されているかを具体的に指定します。
画像をクリックして拡大します。
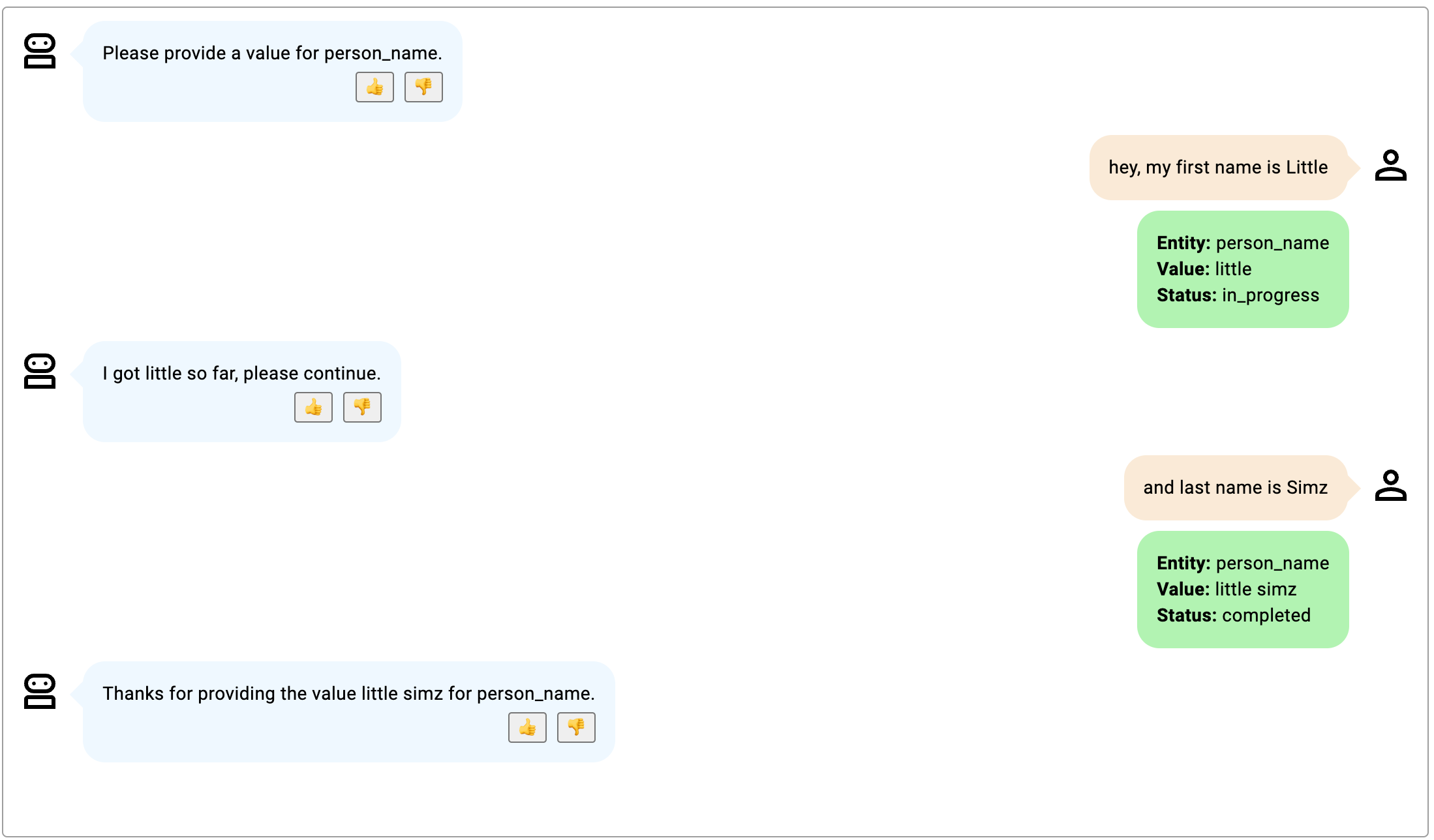
- ボット参加者は、最初のターンで名前のどの部分が提供されたかのみを言及します。モデルでは、ボット参加者が提供する次のサブエンティティは姓であると想定されます。
画像をクリックして拡大します。
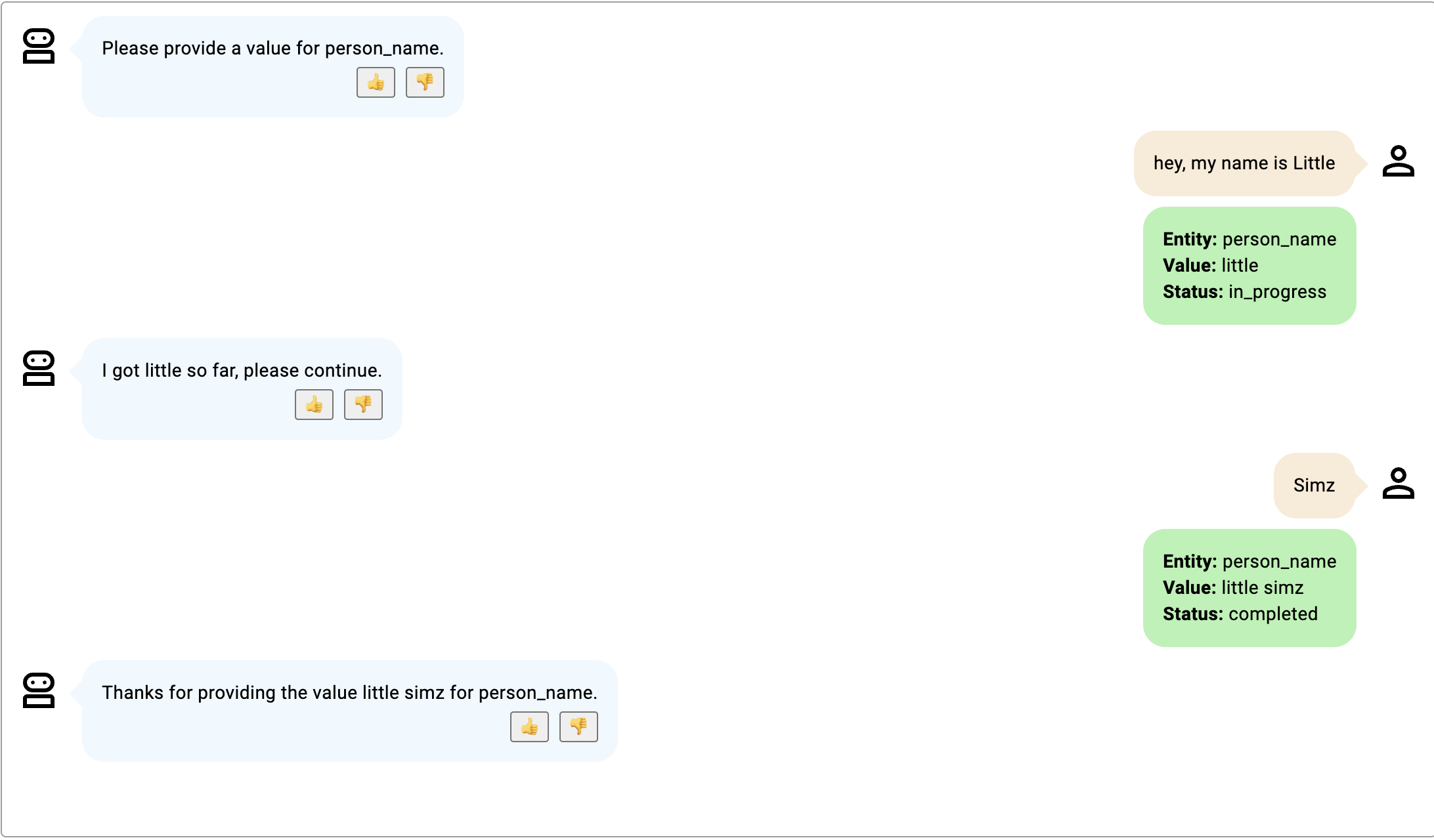
- 両方のサブエンティティが一度に提供され、最初のターン後にステータスが完了に変わります。
画像をクリックして拡大します。
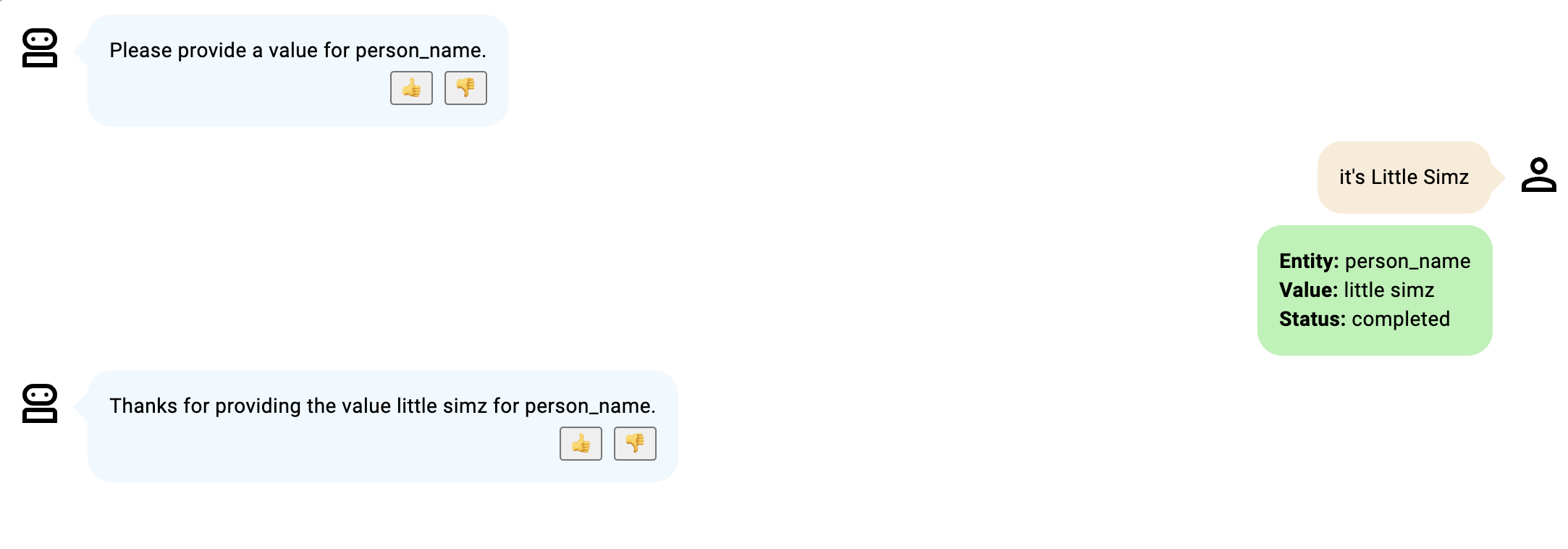
- ボット参加者は、提供されているエンティティが説明に記載されていないミドルネームであると指定しているため、ステータスは進行中のままです。ボット参加者が提供する次のエンティティは、予想どおり姓であると想定されます。
画像をクリックして拡大します。
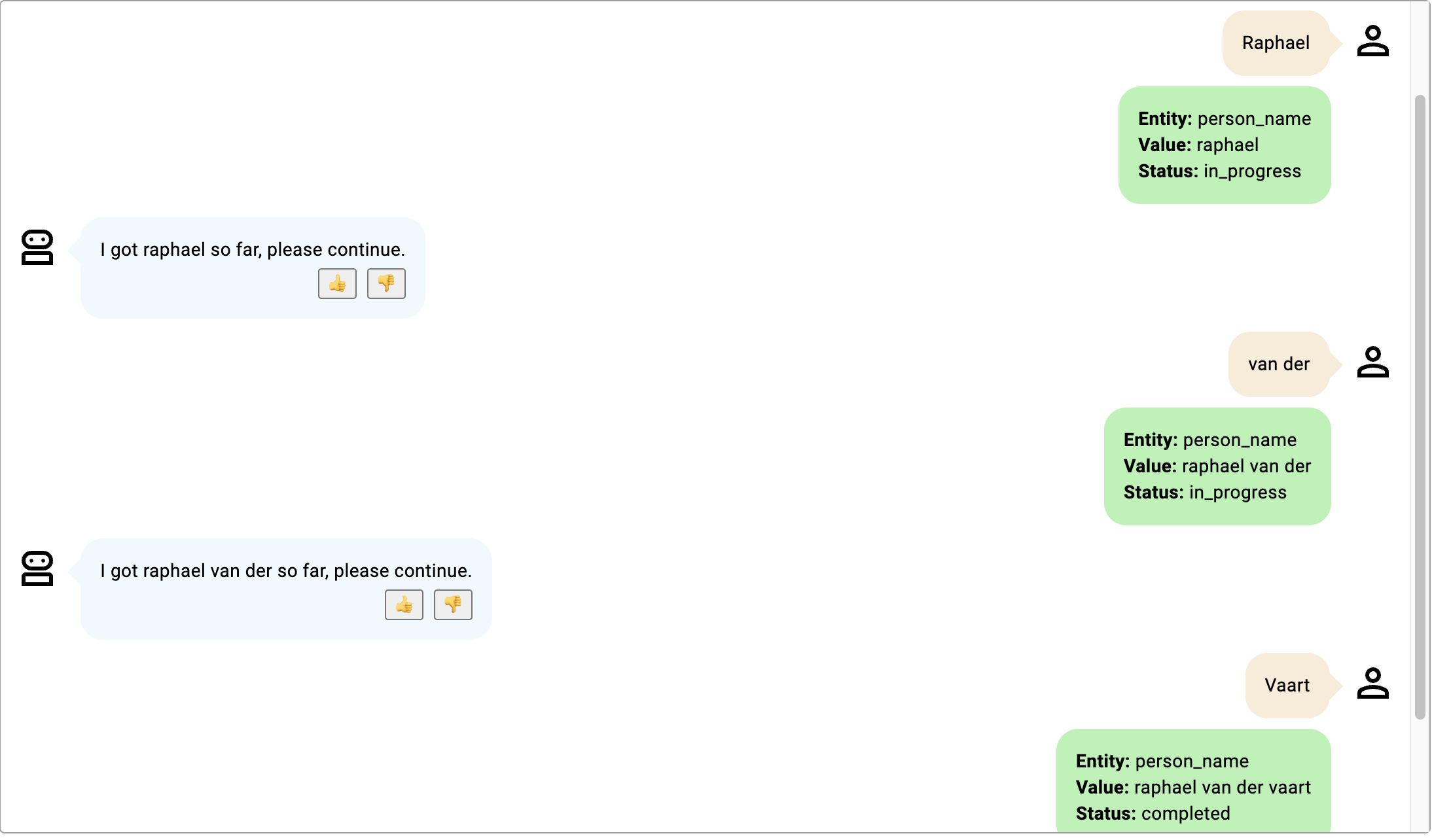
- ボット参加者は指定しておらず、「van der」は姓であると想定されるはずですが、「van der」はよく使用される姓の接頭辞であり、実際の姓ではないため、おそらくそうではありません。
画像をクリックして拡大します。
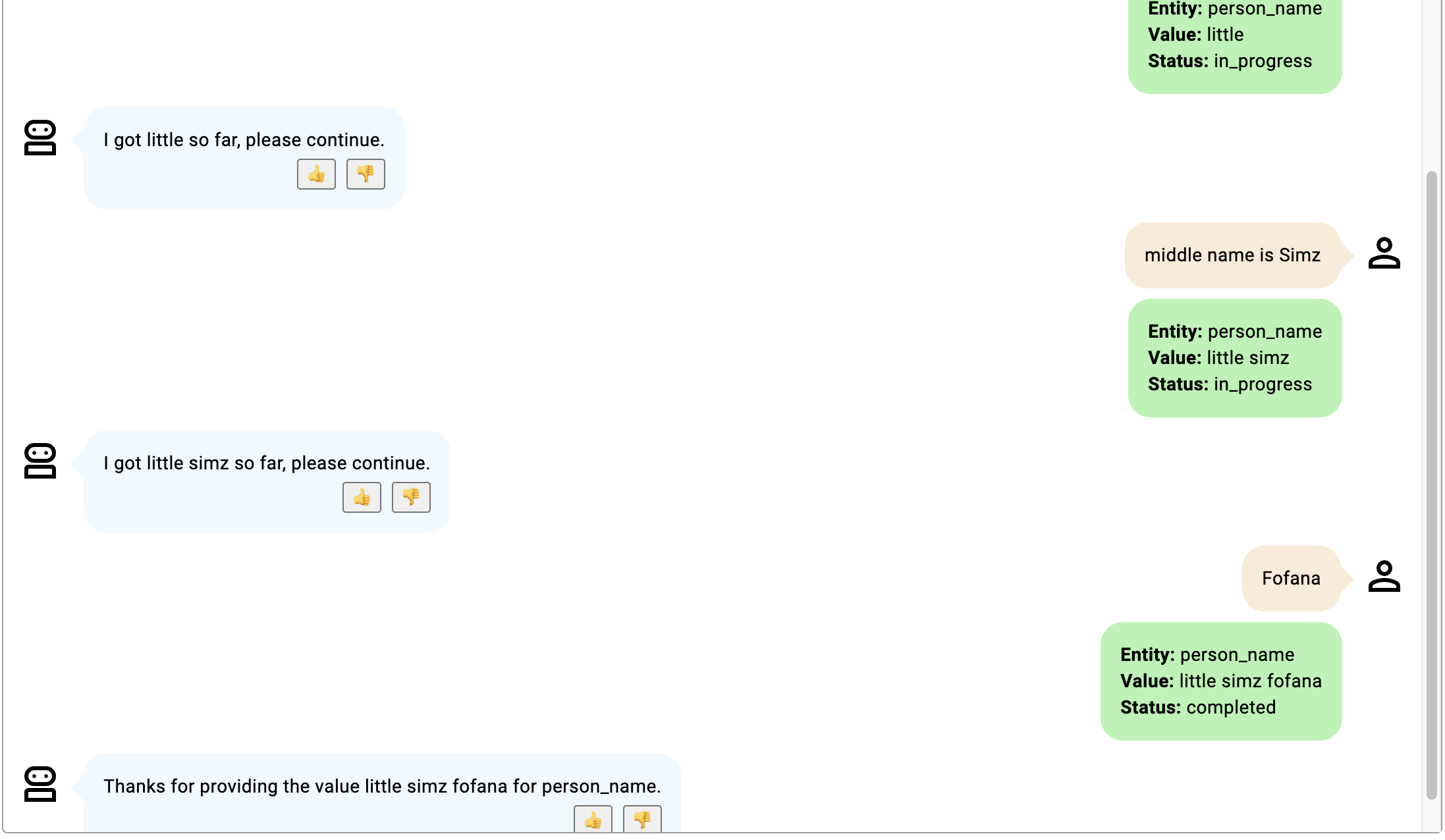
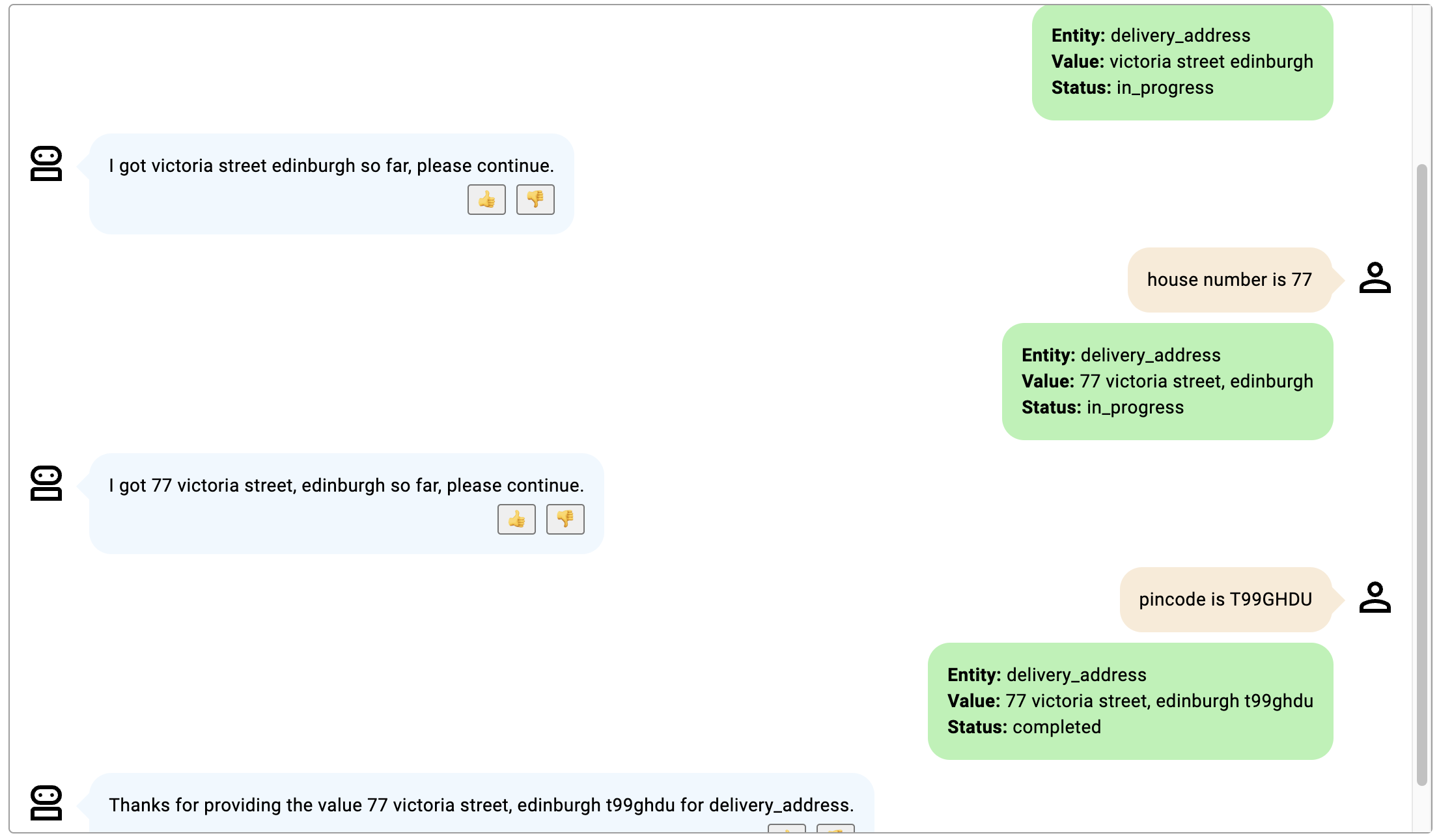
これらの例では、スロットは、家番号と PIN コードを含む配送先住所を記述する delivery_address です。
- 会話は、住所番号と PIN コードの両方が提供されるまで継続され、住所の先頭に住所番号が追加され、最後に PIN コードが追加されます。
画像をクリックして拡大します。
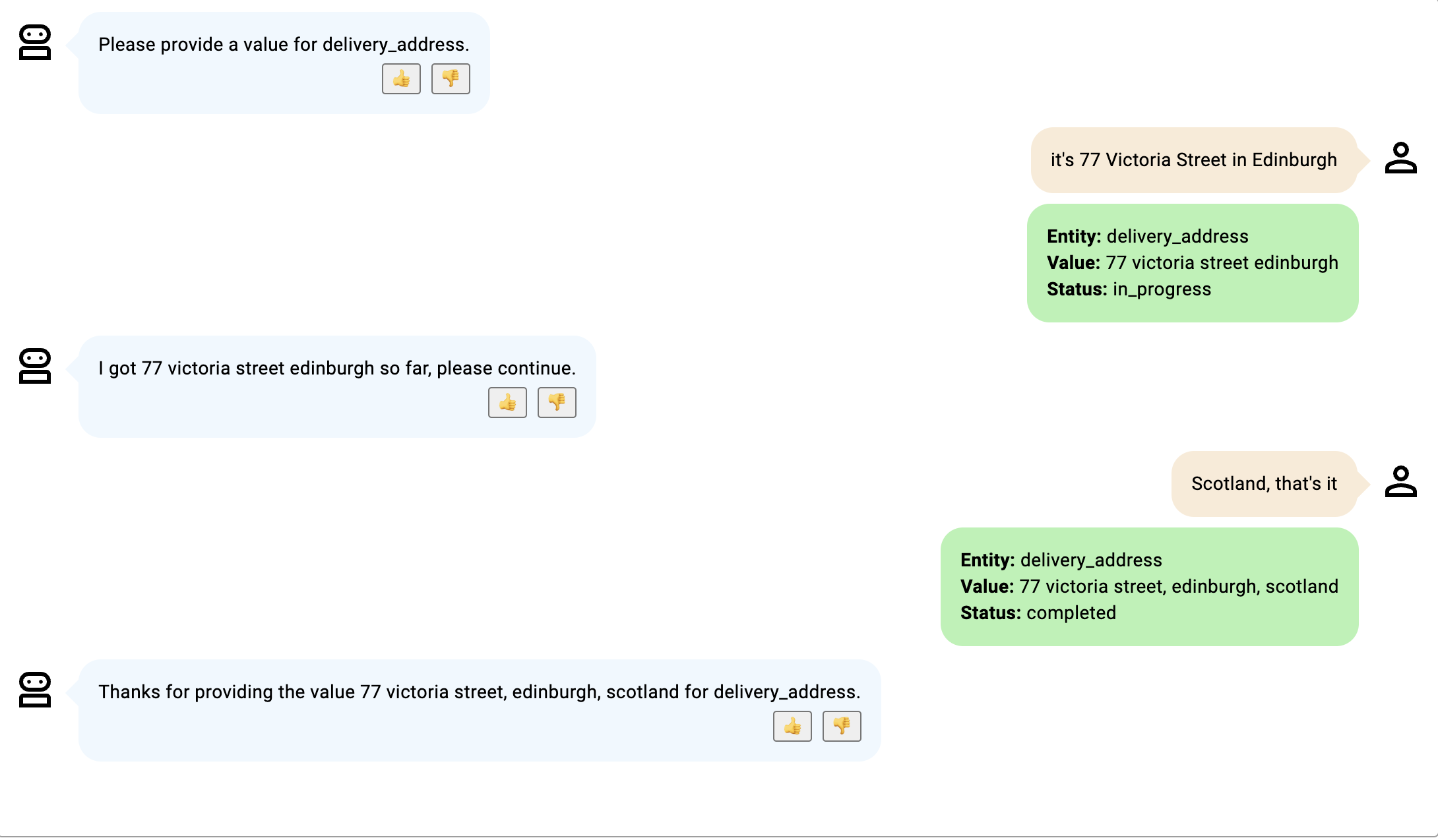
- PIN コードが提供されなかったにもかかわらず、ボット参加者が完了したことを示したため、ステータスは完了に変わります。参加者が「これで終わりです」と言わない場合はこのステータスは発生せず、PIN コードが提供された場合にのみステータスが完了になります。
画像をクリックして拡大します。
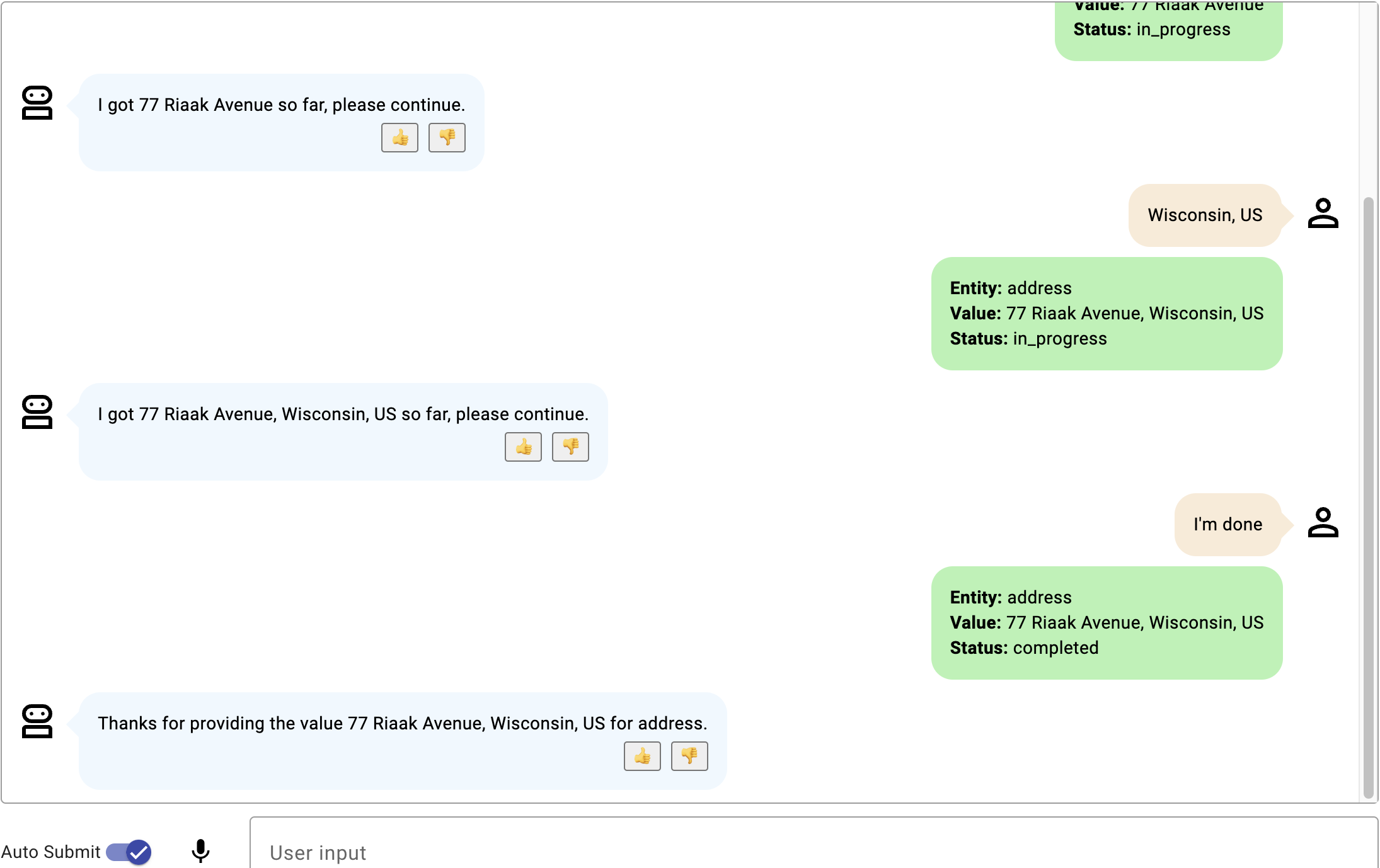
フリーフォームスロットの例:早期退出行動
これらの例では、家番号と PIN コードを使用して配送先住所を記述する delivery_address スロットの早期終了動作シナリオについて説明します。
- 例1 早期退出の例
画像をクリックして拡大します。
- 例 2 早期終了の例。
画像をクリックして拡大します。
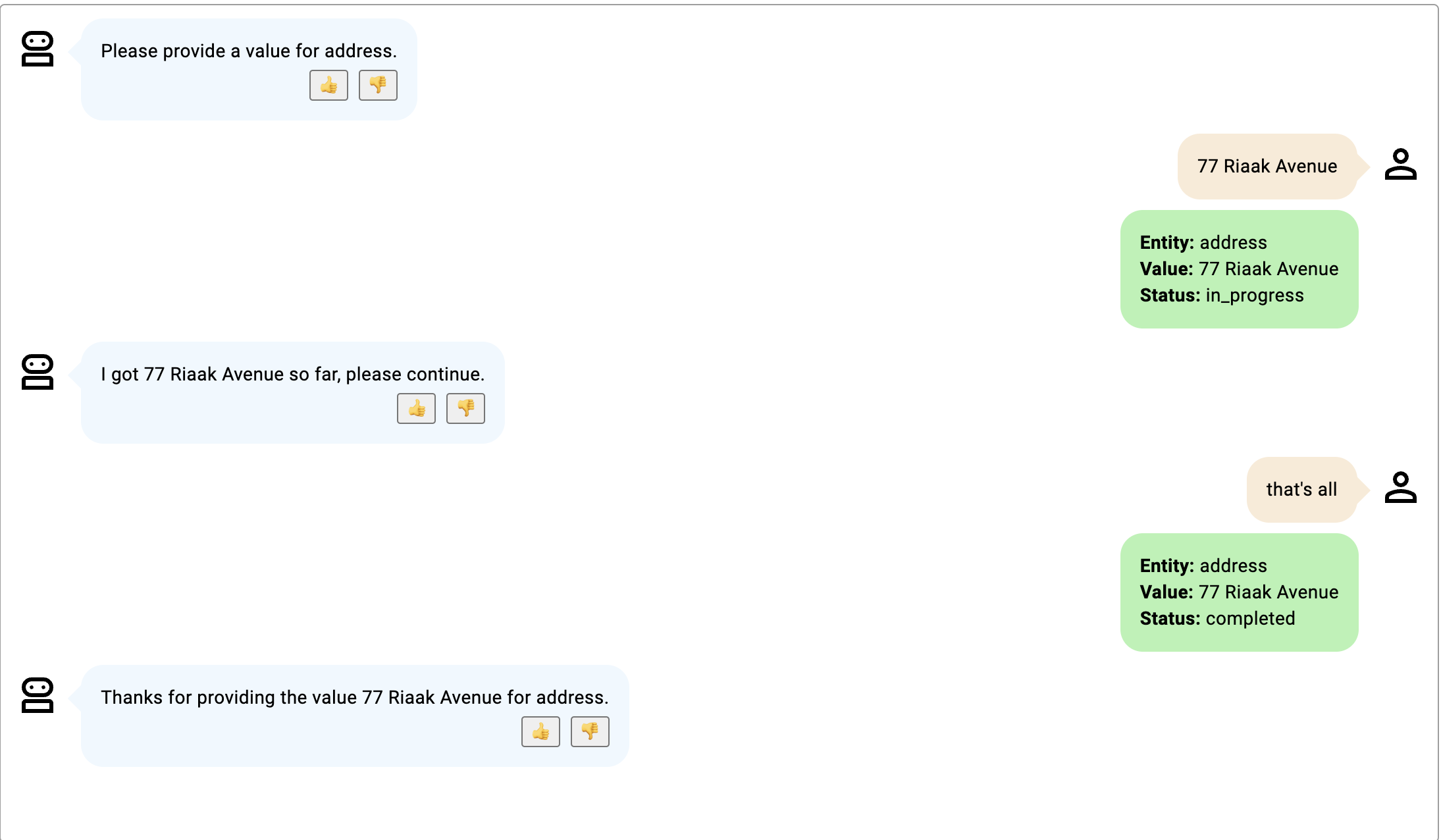
- 例3 早期終了の例。
画像をクリックして拡大します。

- 例4 早期終了の例。
画像をクリックして拡大します。

フリーフォームスロットキャプチャの仕組みを示すサンプル会話の詳細については、以下を参照してください。フリーフォームスロットキャプチャの例。
一般的な考慮事項
- スロット抽出の品質は、音声チャネルでのオーディオからテキストへの転写の品質によって決まります。転写エラーが広がるため、「ゴミを入れればゴミが出てくる」という概念がここに当てはまります。
- 顧客へのプロンプト メッセージには、エンティティが 1 ターンまたは複数ターンで提供できることを記載する必要があります。